


7 steps & 4 pitfalls in (Industrial) Data-Driven Projects
And some personal data stories...


Whether you are a manager or a data specialist, there are the 7 steps you need to know to make any Data-Driven project a success. As you already know, in the IT/OT Insider, we want to bring you not only the theory, but also the pitfalls and our own experiences and apply them to the Operational world.
Enjoy our latest article!
Make sure to subscribe and why not follow David or Willem on LinkedIn?
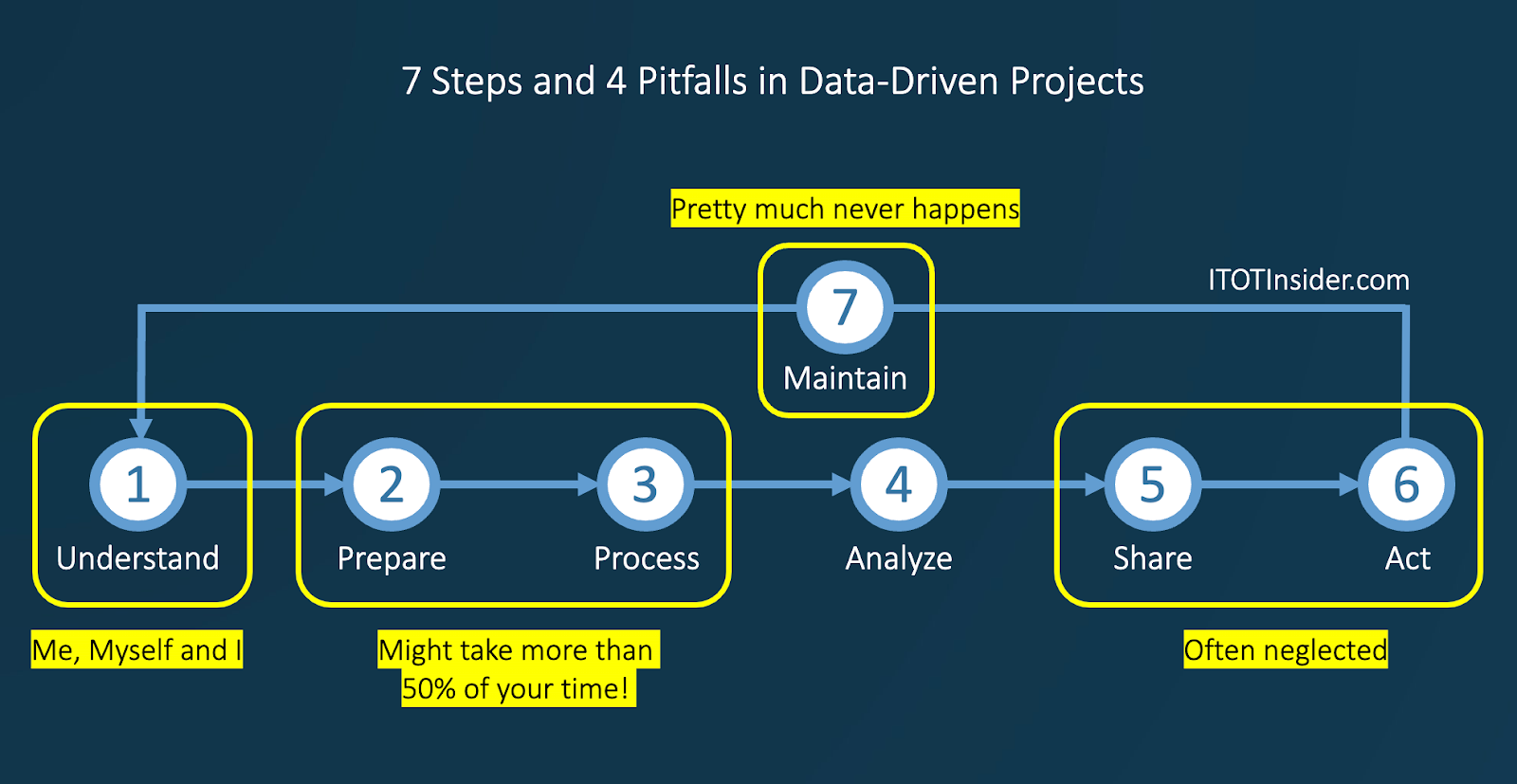
Understand the problem (1)
Identify the business problem to solve. Here are some examples:
Chemical Industry: Predict the formation of (undesirable) foam in a reactor
Wastewater: Anticipate periods of heavy rain and their impact on the wastewater holding tanks
Batch process: Predict the final quality of a batch given the current conditions (and in a next step: suggest changes during a batch resulting in the desired outcome)
Here is our “mind blowing super tip” of the day:
Understand the actual Physical Problem you are trying to solve!
Solving problems isn’t about throwing some pieces of data into a computer and then waiting for the output. We’ve seen clever people coming in with their newest technologies and they fail. They start finding correlations which can simply not exist if you understand the physical process. So, start by understanding the process: go out and look. Take the diagrams. Read. Talk to operators and process engineers.
Pitfall 1: Don't think it's a good idea to hire a data scientist and then park him or her in a global team, waiting for the next phone call: “Please come, do your magic and help us with this problem!”. Data science expertise should be embedded into the business. When projects are executed, a multidisciplinary team should be assembled, it’s not “me, myself and I”. By combining process and data science knowledge, the right assumptions can be validated fast. Add a data and/or infrastructure engineer to the equation to make sure you don’t get stuck in the next step. Finally, start thinking about who will be using the final result and make sure to include some (super) users as fast as possible. This will speed up the acceptance (change) process.
Prepare (2) & Process (3)
Do we have data? Find and collect it. Decide on the data formats and interpolation you will be using.
Not enough data available? Maybe you decide to either postpone the project and wait for more data, require additional sensors or quality measurements to be installed, or maybe you will design an experiment in order to make small (but relevant) changes to the process.
Preprocess relevant data for the model. This includes data cleaning, feature engineering, data augmentation, and data splitting into training, validation and testing sets.
In the Manufacturing industry, this part is typically the most time consuming. Data is in many cases split between the Historian (time series data store), a Laboratory system (if quality data is needed), a Manufacturing Execution System (e.g. for batch or product information), the ERP system and many more. Once you start collecting and combining data, you will also inevitably have to face data quality issues (stale sensors, noisy data, wrong manual inputs,...)
Pitfall 2: Although good solutions to gather and transform datasets are available, most projects will spend up to 50% of the project time in data collection, transforming and cleaning. Make sure your organization acknowledges that (OT) data should be available to everyone in the organization. Investing in an OT Data Platform is still far fetched for many, but should be on top of your agenda. This includes: integration of multiple (time series) data sources, access to asset and production context, data management, quality & observability. More about this in one of our next articles, make sure to subscribe!
Side note: In some cases we rely on manual data inputs. This is notoriously difficult to use and extremely error prone. We performed a real life experiment a couple of years ago to showcase this.
We asked a team of operators to write down 6 simple measurements once per shift during a week. The measurements were visible on their control system and included some basic pressure and temperature readings. They also needed to write down the time. We told them that their work was crucial as there was no other way to measure, they needed to be as precise as possible.
We were a bit sneaky as we could access the actual raw data as well using a process historian. We compared the actual measurements with the manual data input. We believed that there might be some discrepancies, but the actual outcome was worse than expected: the manual recorded records were completely useless. Totally wrong readings, swapped columns, wrong time stamps, missing data, not readable, you name it…
We stopped relying on manual data entry as of that day.
Analyze (4)
Select the model: Choose the appropriate model or algorithm that will best solve the problem. In many cases simple (linear) models can do the job just fine, but sometimes you will need to do some heavy lifting using neural networks, decision trees, or support vector machines.
By understanding the Physical Problem, you will be able to make a better model selection. For example: if you already know your process has serious dead-times / delays between steps, you should take this into account (either by selecting the right model or by transforming the dataset to a set which removes the delays). Or if you know certain parts of your reactor respond in a very non-linear fashion, it might be beneficial to simplify the problem around the reactor.
Train, evaluate, optimize & test the model: Train the model using the training data set. Evaluate the model using the validation data set to check its performance and identify areas of improvement. Optimize the model based on the evaluation results. And finally: test the model on the testing data set to ensure it can generalize well to new data.
Deploy the model: Deploy the model in a production environment, integrating it with the necessary systems and processes. This includes monitoring the model's performance and updating it as needed.
While most models will be developed in data science environments (which might run in the cloud or on a local computer), the deployment of those models in the Manufacturing world typically takes place in an Edge/On Premise environment. A good data science project for Manufacturing takes the architectural requirements (security, availability, speed etc) into account early in the project as this too will have a great impact on the success rate of your project.
Share (5) & Act (6)
Hopefully you found some great insights. It’s time to share those with your peers. If you made the right decision to include some of the actual users in your project this will be very easy! Make sure to use tools and dashboards which are easy to share and update.
After sharing your work, come together with a team of experts to act upon the advice given. Not acting, means that you are throwing the money spent in the data project away.
Pitfall 3: Don’t make the same mistake as David did in the beginning of his career. One of his very first Machine Learning projects back in 2010 was using Decision Tree Learning to predict the formation of an unwanted residual in a chemical process. The model gave an indication whether or not the process had to be stopped to avoid this to happen. The process operators were not directly involved and had to rely on a mathematical model they didn’t understand. There was no way to see or measure the formation of this residual using traditional techniques. They called David’s model “The Oracle” and sure enough, as soon as they could, they abandoned the use of the model and went back to their trial and error approach. In hindsight, the operators were not involved in the “why and how” and didn’t trust the outcomes.
Maintain (7)
Continuously maintaining and improving the model by monitoring its performance, retraining it on new data, and updating it with new features or algorithms is a must do: plants change over time, other raw materials are used or process conditions are changed. When you miss out on transferring those changes to your models, they will become obsolete fast. A continuous improvement cycle is essential which includes good versioning of your models.
Last but not least continuous feedback about those changes to operators and other users of the model is essential for them to keep on accepting the work you have done.
Pitfall 4: In many (most) cases, models are introduced in a “set and forget” way. Over time this leads to degradation of the results, resulting in distrust by the users and ultimately your work will be switched off (or just be ignored). This can be avoided by introducing a service concept when your work transitions from project to ongoing modus.
From the point of view of the business, this should become a Continuous Improvement process including regular reviews of the model performance together with process experts. At times, it will be enough to make some minor tweaks. At other times, it might be decided to restart back at step 1, which is totally OK!
From the Technology perspective, you will need to make sure that whatever systems and software used are kept up to date.
Our summary for your next PowerPoint presentation
Understand the Problem
Identify and comprehend the problem, focus on understanding the physical processes.Embed Data Science Expertise
Embed data science expertise within the business, assembling multidisciplinary teams and involving end-users early.Build your OT Data Platform
Ensure data is easily available. Working with time series data has some challenges other than the one your data scientist might be used to.Effective Analysis
Carefully select and optimize models based on physical problem insights and deploy them in suitable environments.Start the Continuous Improvement Process
Share insights, act upon recommendations, and continuously maintain and improve models for ongoing success.